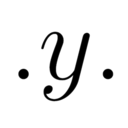勾配法
(サイエンス)
【こうばいほう】
最適化問題のアルゴリズムのうち、関数の勾配を使うアルゴリズムの総称。
ほぼ全ての勾配法のアルゴリズムが最小解ではなく局所解を探索するアルゴリズムとなっている。そのため、多数の初期値から探索を行う必要がある。また、どのような局所解にたどり着くかは初期値の影響を受けるため、適切な初期値を選択する必要がある。
最適化問題のアルゴリズムのうち、関数の勾配を使うアルゴリズムの総称。
ほぼ全ての勾配法のアルゴリズムが最小解ではなく局所解を探索するアルゴリズムとなっている。そのため、多数の初期値から探索を行う必要がある。また、どのような局所解にたどり着くかは初期値の影響を受けるため、適切な初期値を選択する必要がある。


 cocu.hatenablog.com
cocu.hatenablog.com
 qiita.com
qiita.com
 speakerdeck.com
speakerdeck.com
 qiita.com
qiita.com
 aidiary.hatenablog.com
aidiary.hatenablog.com
 aidiary.hatenablog.com
aidiary.hatenablog.com
 gihyo.jp
gihyo.jp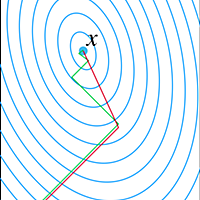
 ja.wikipedia.org
ja.wikipedia.org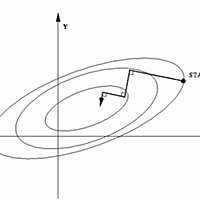
 zellij.hatenablog.com
zellij.hatenablog.com